Lecture Five: Practical Kubernetes
We covered the conceptual foundation and some of the basic Kubernetes resources last week, and this week we’ll be diving into more concepts and resource types in Kubernetes that build on top of the foundation we built. Each resource we cover will have an associated example with requisite yaml. Please make sure to also check out the Kubernetes documentation as well! The important thing isn’t to memorize the yaml, but to understand the concepts so we can extend our understanding of what Kubernetes can do.
Namespaces
Namespaces are a way to separate resources by a common name. They’re useful for organization as well as permissioning. While most Kubernetes resources are scoped to a namespace, resources having to do with the whole cluster are not (e.g. ClusterRoleBindings). Namespaces aren’t a foolproof way to separate resources within a cluster, because they don’t provide any strong security guarantees.
apiVersion: v1
kind: Namespace
metadata:
name: cphalen
Two namespaces are available by default in a cluster: default for your own resources and kube-system, for resources the cluster needs to run itself. You can get resources belonging to a certain namespace with by adding -n <namespace> to a kubectl get command.
Secret
Secrets are used to store sensitive runtime information such as API keys, username/passwords, or certificates that shouldn’t be stored in source code. Secrets are stored as base64 in the API server. On the container, they can be mounted to files or exported to environment variables. Note that while they are base64 encoded and are called “Secrets”, if an attacker gains admin privileges on the Kubernetes API they can just decode the Secrets from base64 and read them. So, while Secrets are intended to be for sensitive information, they do not actually provide protection against an attacker if the attacker gets the read:secret permission.
The default secret type is Opaque which can be used to store arbitrary data. Other types of Secrets can be used for specific sensitive information (such as SSH credentials or TLS data).
The example below will mount the contents of the Secret as two files, /etc/auth/username and /etc/auth/password. The mountPath of the volume is the directory where the secret files are then generated in.
---
apiVersion: v1
kind: Secret
metadata:
name: basic-auth
type: kubernetes.io/basic-auth
stringData:
username: admin
password: t0p-Secret
---
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: redis
volumeMounts:
- name: auth
mountPath: "/etc/auth"
readOnly: true
volumes:
- name: auth
secret:
secretName: basic-auth
ConfigMap
ConfigMaps are for non-sensitive runtime configuration. Similar to Secrets, ConfigMaps can be mounted to files or exported to environment variables. ConfigMaps allow you to separate your configuration from your actual code and business logic. This means you don’t have to rebuild container images whenever you change configuration.
ConfigMap data can also be mounted as either files or environment variables inside the container.
apiVersion: v1
kind: ConfigMap
metadata:
name: game-demo
data:
# property-like keys; each key maps to a simple value
player_initial_lives: "3"
ui_properties_file_name: "user-interface.properties"
# file-like keys
game.properties: |
enemy.types=aliens,monsters
player.maximum-lives=5
user-interface.properties: |
color.good=purple
color.bad=yellow
allow.textmode=true
Jobs and Cronjobs
A Job is a short-lived containers that are intended to run a specific task. CronJobs allow Jobs to be run on schedules. The scheduling syntax is the same scheduling format as Cron in Unix. You can use the tool https://crontab.guru/ to select the correct schedule.
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hello
spec:
# This schedule is once per hour
schedule: "0 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- date; echo Hello from the Kubernetes cluster
restartPolicy: OnFailure
Why do we have to nest four or five YAML objects with template and spec just to run a job on a schedule? The answer comes down to modularity and the construction of the API. A CronJob is just a Job with a schedule, and a Job is in turn just a Pod that runs to completion. Kubernetes takes advantage of this conceptual hierarchy, and embeds references to API objects within API objects. In a quite literal sense, a CronJob has a Job, which in turn has a Pod. While this modularity results in more complex YAML, it makes it much easier for us to reason about resources which are simply compositions of other resources.
Volumes
Volumes are a way to reference some kind of non-ephemeral, persistent storage from within the cluster. They’re used to provide filesystem-based persistence across application restarts or (in some cases) node reschedules. There are PersistentVolumes (PV) which is a physical representation of a disk in the API. Then we have PersistentVolumeClaims (PVCs) which is a request for access to a PersistentVolume. Then we can bind PVCs to PVs.
A PV is really a representation of the physical block where storage exists, and the PVC is a request to access that storage. This feels a little over-engineered, but it is actually really helpful when using cloud services like AWS where volumes are allocated independently of the machine running the containers.
This is one of the key components of Kubernetes that lets us treat our serves as cattle, not pets. When volumes and storage are separated from our application code, we’re able to separate our concerns around running our code from persisting our data.
StatefulSet
StatefulSet is a deployment where each pod gets a persistent volume. This is used for applications that need to be resistant to reboots. Common applications include:
- Distributed Databases: MongoDB, CockroachDB, Cassandra
- Games: Minecraft
- Search: AWS Elasticsearch
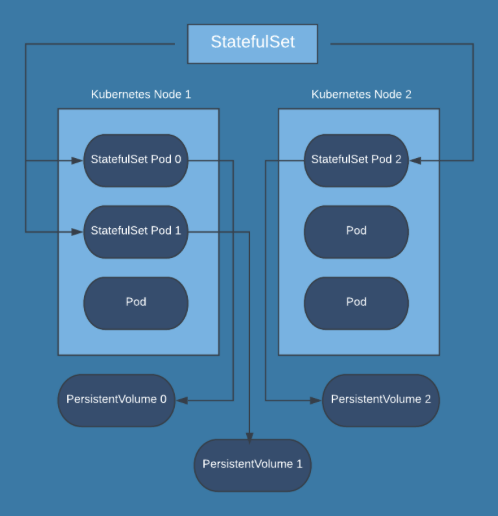
Note that each StatefulSet has its own PersistentVolume, and so writes to PersistentVolume 0 from Pod 0 in the diagram will not be readable from either Pod 1 or Pod 2. The application itself will need to coordinate the state of the PersistentVolumes using some kind of replication strategy.
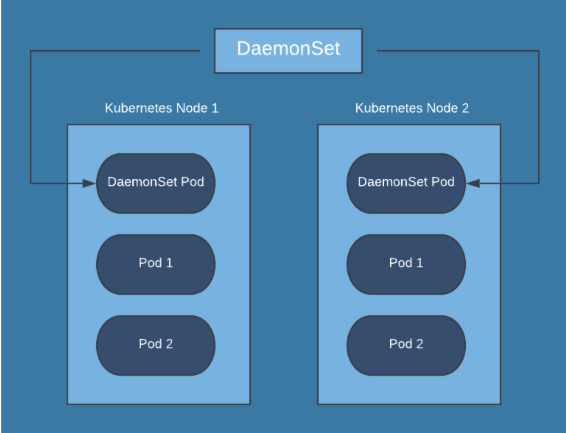
DaemonSet
A DaemonSet is a deployment which has one pod running on each node in the cluster. These are used to provide node-wide services like authentication gateways, ingress routers, and log collectors.
Annotations
Annotations aren’t resources on their own, but a type of resource metadata used to store auxillary key/value information about a resource. Unlike labels, resources can’t be queried by annotations. Annotations aren’t used by Kubernetes itself, but other software in and around your cluster might use the extra metadata to determine its own behavior.
apiVersion: v1
kind: Pod
metadata:
name: annotations-demo
annotations: # can be any key/value combination
imageregistry: "https://hub.docker.com/"
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80